
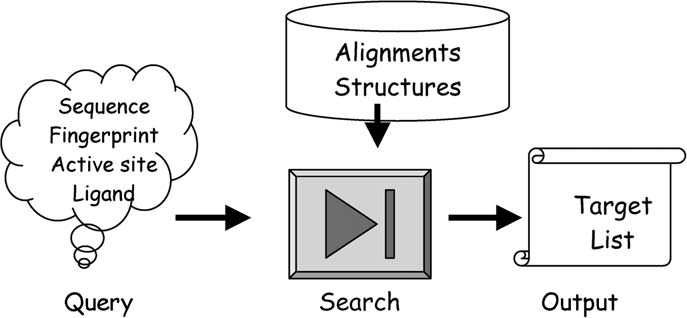
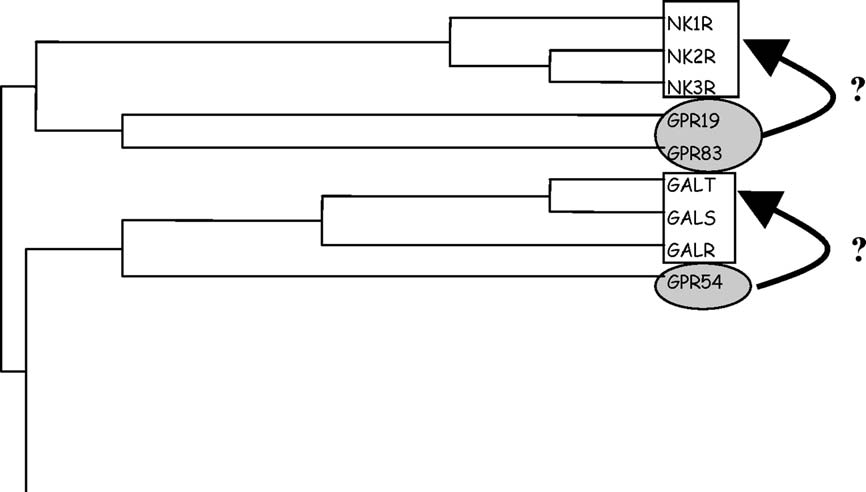
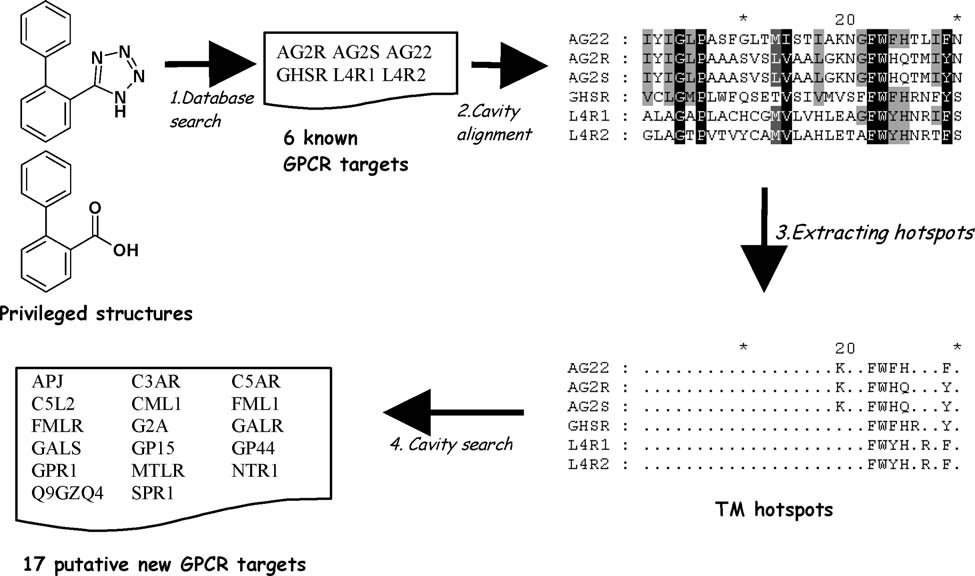
Diseases of goat
The common diseases of goat, their symptoms, treatment, and methods used in Sindh-Pakistan. By Mrs. Farzana Panhwar, July 2005 Author: Farzana Panhwar (Mrs) Address: 157-C, Unit No.2, Latifabad, Hyderabad (Sindh), Pakistan [email protected]