Levitra enthält Vardenafil, das eine kürzere Wirkdauer als Tadalafil hat, dafür aber schnell einsetzt. Männer, die diskret bestellen möchten, suchen häufig nach levitra kaufen ohne rezept. Dabei spielt die rechtliche Lage in der Schweiz eine wichtige Rolle.
Biotext.berkeley.edu
Noun Compound Interpretation
Using Paraphrasing Verbs: Feasibility Study
Preslav Nakov
??
Linguistic Modeling Department,
Institute for Parallel Processing,
Bulgarian Academy of Sciences
25A, Acad. G. Bonchev St., 1113 Sofia, Bulgaria
Department of Mathematics and Informatics,
Sofia University,
5, James Bourchier Blvd., 1164 Sofia, Bulgaria
Abstract. The paper addresses an important challenge for the auto-matic processing of English written text: understanding noun compounds'semantics. Following Downing (1977) [1], we define noun compounds assequences of nouns acting as a single noun, e.g.,
bee honey,
apple cake,
stem cell, etc. In our view, they are best characterised by the set of allpossible paraphrasing verbs that can connect the target nouns, with as-sociated weights, e.g.,
malaria mosquito can be represented as follows:
carry (23),
spread (16),
cause (12),
transmit (9), etc. These verbs are di-rectly usable as paraphrases, and using multiple of them simultaneouslyyields an appealing fine-grained semantic representation.
In the present paper, we describe the process of constructing such rep-resentations for 250 noun-noun compounds previously proposed in thelinguistic literature by Levi (1978) [2]. In particular, using human sub-jects recruited through Amazon Mechanical Turk Web Service, we createa valuable manually-annotated resource for noun compound interpreta-tion, which we make publicly available with the hope to inspire furtherresearch in paraphrase-based noun compound interpretation. We furtherperform a number of experiments, including a comparison to automat-ically generated weight vectors, in order to assess the dataset qualityand the feasibility of the idea of using paraphrasing verbs to characterisenoun compounds' semantics; the results are quite promising.
Key words: Noun Compounds, Lexical Semantics, Paraphrasing.
?? Part of this research was performed while the author was a PhD student at the
EECS department, Computer Science division, University of California at Berkeley.
An important challenge for the automatic analysis of English written text isposed by noun compounds – sequences of nouns acting as a single noun1, e.g.,
colon cancer tumor suppressor protein – which are abundant in English: Bald-win&Tanaka'04 [3] calculated that noun compounds comprise 3.9% and 2.6% ofall tokens in the
Reuters corpus and the
British National Corpus2, respectively.
Understanding noun compounds' syntax and semantics is difficult but impor-
tant for many natural language applications (NLP) including but not limited toquestion answering, machine translation, information retrieval, and informationextraction. For example, a question answering system might need to determinewhether ‘
protein acting as a tumor suppressor' is a good paraphrase for
tumorsuppressor protein, and an information extraction system might need to decidewhether
neck vein thrombosis and
neck thrombosis could possibly co-refer whenused in the same document. Similarly, a machine translation system facing theunknown noun compound
WTO Geneva headquarters might benefit from beingable to paraphrase it as
Geneva headquarters of the WTO or as
WTO headquar-ters located in Geneva. Given a query like
migraine treatment, an informationretrieval system could use suitable paraphrasing verbs like
relieve and
preventfor page ranking and query refinement.
Throughout the rest of the paper, we hold the view that noun compounds'
semantics is best characterised by the set of all possible paraphrasing verbs thatcan connect the target nouns, with associated weights, e.g.,
malaria mosquitocan be represented as follows:
carry (23),
spread (16),
cause (12),
transmit (9),etc. Such verbs are directly usable as paraphrases, and using multiple of themsimultaneously yields an appealing fine-grained semantic representation.
The remainder of the paper is organised as follows: Section 2 provides a short
overview of the different representations of noun compounds' semantics previ-ously proposed in the literature. Section 3 gives details on the process of creatinga lexicon of human-proposed paraphrasing verbs for 250 noun-noun compounds.
Section 4 describes the experiments we performed in order to assess the lexicon'squality and the feasibility of using paraphrasing verbs to characterise noun com-pounds' semantics. Section 5 contains a discussion on the applicability of theapproach. Section 6 concludes and suggests possible directions for future work.
The dominant view in theoretical linguistics is that noun compound semanticscan be expressed by a small set of abstract relations. For example, in the theoryof Levi [2], complex nominals – a general concept grouping together the partiallyoverlapping classes of nominal compounds (e.g.,
peanut butter), nominalisations
1 This is Downing's definition of noun compounds [1], which we adopt throughout the
rest of the paper.
2 There are 256K distinct noun compounds out of the 939K distinct wordforms in the
100M-word
British National Corpus.
Noun Compound Interpretation Using Paraphrasing Verbs
Example Subj/obj Traditional Name
CAUSE1
tear gas
CAUSE2
drug deaths
subject causative
HAVE1
apple cake
HAVE2
lemon peel
MAKE1
silkworm
MAKE2
snowball
steam iron
soldier ant
field mouse
horse doctor
ABOUT
price war
Table 1. Levi's recoverably deletable predicates (RDPs). Column 3 shows themodifier's function in the corresponding paraphrasing relative clause: when the modifieris the subject of that clause, the RDP is marked with the index 2.
parental refusal
dream analysis city land acquisition
Product
clerical errors
musical critique student course ratings
city planner
Patient
student inventions
Table 2. Levi's nominalisation types with examples.
(e.g.,
dream analysis), and nonpredicate noun phrases (e.g.,
electric shock) – canbe derived by the following two processes:
1. Predicate Deletion. It can delete the 12 abstract recoverably deletable
predicates (RDPs) shown in Table 1, e.g.,
pie made of apples → apple pie.
In the resulting nominals, the modifier is typically the object of the predicate;when it is the subject, the predicate is marked with the index 2;
2. Predicate Nominalisation. It produces nominals whose head is a nom-
inalised verb, and whose modifier is derived from either the subject orthe object of the underlying predicate, e.g.,
the President refused generalMacArthur's request → presidential refusal. Multi-modifier nominalisationsretaining both the subject and the object as modifiers are possible as well.
Therefore, there are three types of nominalisations depending on the modi-fier, which are combined with the following four types of nominalisations thehead can represent:
act,
product,
agent and
patient. See Table 2 for examples.
In the alternative linguistic theory of Warren [4], noun compounds are organ-
ised into a four-level hierarchy, where the top level is occupied by the following sixmajor semantic relations: Possession, Location, Purpose, Activity-Actor,Resemblance, and Constitute. Constitute is further sub-divided into finer-grained level-2 relations: Source-Result, Result-Source or Copula. Further-more, Copula is sub-divided into the level-3 relations Adjective-Like Modifier,
Subsumptive, and Attributive. Finally, Attributive is divided into the level-4relations Animate Head (e.g.,
girl friend) and Inanimate Head (e.g.,
house boat).
A similar view is dominant in computational linguistics. For example, Nas-
tase&Szpakowicz [5] proposed a two-level hierarchy consisting of thirty fine-grained relations, grouped into the following five coarse-grained ones (the cor-responding fine-grained relations are shown in parentheses): CAUSALITY (cause,effect, detraction, purpose), PARTICIPANT (agent, beneficiary, instrument,object property, object, part, possessor, property, product, source, whole,stative), QUALITY (container, content, equative, material, measure, topic,type), SPATIAL (direction, location at, location from, location), andTEMPORALITY (frequency, time at, time through). For example,
exam anxietyis classified as effect and therefore also as CAUSALITY.
Similarly, Girju&al. [6] propose a set of 21 abstract relations (POSSESSION,
ATTRIBUTE-HOLDER, AGENT, TEMPORAL, PART-WHOLE, IS-A, CAUSE, MAKE/PRODUCE,INSTRUMENT, LOCATION/SPACE, PURPOSE, SOURCE, TOPIC, MANNER, MEANS, THEME,ACCOMPANIMENT, EXPERIENCER, RECIPIENT, MEASURE, and RESULT) and Rosario& Hearst [7] use 18 abstract domain-specific biomedical relations (e.g., Defect,Material, Person Afflicted).
An alternative view is held by Lauer [8], who defines the problem of noun
compound interpretation as predicting which among the following eight prepo-sitions best paraphrases the target noun compound: of, for, in, at, on, from,with, and about. For example,
olive oil is
oil from olives.
Lauer's approach is attractive since it is simple and yields prepositions rep-
resenting paraphrases directly usable in NLP applications. However, it is alsoproblematic since mapping between prepositions and abstract relations is hard[6], e.g., in, on, and at, all can refer to both LOCATION and TIME.
Using abstract relations like CAUSE is problematic as well. First, it is un-
clear which relation inventory is the best one. Second, being both abstractand limited, such relations capture only part of the semantics, e.g., classify-ing
malaria mosquito as CAUSE obscures the fact that mosquitos do not directlycause malaria, but just transmit it. Third, in many cases, multiple relations arepossible, e.g., in Levi's theory,
sand dune is interpretable as both HAVE and BE.
Some of these issues are addressed by Finin [9], who proposes to use a specific
verb, e.g.,
salt water is interpreted as
dissolved in. In a number of publications[10–12], we introduced and advocated an extension of this idea, where nouncompounds are characterised by the set of all possible paraphrasing verbs, withassociated weights, e.g.,
malaria mosquito can be
carry (23),
spread (16),
cause(12),
transmit (9),
etc. These verbs are fine-grained, directly usable as para-phrases, and using multiple of them for a given noun compound approximatesits semantics better.
Following this line of research, below we describe the process of building a
lexicon of human-proposed paraphrasing verbs, and a number of experimentsin assessing both the lexicon's quality and the feasibility of the idea of usingparaphrasing verbs to characterise noun compounds' semantics.
Noun Compound Interpretation Using Paraphrasing Verbs
Creating a Lexicon of Paraphrasing Verbs
Below we describe the process of creating a new lexicon for noun compoundinterpretation in terms of multi-sets of paraphrasing verbs. We used the AmazonMechanical Turk Web Service3 to recruit human subjects to annotate 250 noun-noun compounds previously proposed in the linguistic literature.
We defined a special noun-noun compound paraphrasing task, which, given a
noun-noun compound, asks human subjects to propose verbs, possibly followedby prepositions, that could be used in a paraphrase involving
that. For example,
nourish,
run along and
come from are good paraphrasing verbs for
neck veinsince they can be used in paraphrases like ‘
a vein that nourishes the neck', ‘
avein that runs along the neck' or ‘
a vein that comes from the neck'. In an attemptto make the task as clear as possible and to ensure high quality of the results,we provided detailed instructions, we stated explicit restrictions, and we gaveseveral example paraphrases. We instructed the participants to propose at leastthree paraphrasing verbs per noun-noun compound, if possible. The instructionswe provided and the actual interface the human subjects were seeing are shownin Figures 1 and 2.
Fig. 1. Paraphrasing in Mechanical Turk: task introduction.
3 http://www.mturk.com
We used
Amazon Mechanical Turk Web service, which represents a cheap
and easy way to recruit subjects for various tasks that require human intelli-gence. The service provides an API allowing a computer programme to ask ahuman to perform a task and returns the results.
Amazon calls the process
Ar-tificial Artificial Intelligence. The idea behind the latter term and behind theorigin of the service's name come from the
Mechanical Turk, a life-sized woodenchess-playing mannequin the Hungarian nobleman Wolfgang von Kempelen con-structed in 1769, which was able to defeat skilled opponents including BenjaminFranklin and Napoleon Bonaparte. The audience believed the automaton wasmaking decisions using Artificial Intelligence, but the secret was a chess masterhidden inside. Now
Amazon provides a similar service to computer applications.
Fig. 2. Paraphrasing in Mechanical Turk: instructions, example, sample questions.
Noun Compound Interpretation Using Paraphrasing Verbs
We used the 387 complex nominals Levi studied in her theory, listed in the
appendix of [2]. We had to exclude the examples with an adjectival modifier,which are allowed in that theory, but do not represent noun compounds underour definition as was mentioned above. In addition, the following compoundswere written concatenated and we decided to exclude them as well:
whistleberries,
gunboat,
silkworm,
cellblock,
snowball,
meatballs,
windmill,
needlework,
textbook,
doghouse, and
mothballs. Some other examples contained a modifier that is aconcatenation of two nouns, e.g.,
wastebasket category,
hairpin turn,
headachepills,
basketball season,
testtube baby; we decided to retain these examples. Asimilar example (which we chose to retain as well) is
beehive hairdo, where boththe modifier and the head are concatenations. As a result, we ended up with 250good noun-noun compounds out of the original 387 complex nominals.
We randomly distributed these 250 noun-noun compounds (below, we will
be referring to them as the
Levi-250 dataset) into groups of 5, which yielded 50Mechanical Turk tasks known as HITs (
Amazon Human Intelligence Tasks), andwe requested 25 different human subjects (
Amazon workers) per HIT. We hadto reject some of the submissions, which were empty or were not following theinstructions, in which cases we requested additional workers in order to guaranteeat least 25 good submissions per HIT. Each human subject was allowed to workon any number of HITs (between 1 and 50), but was not permitted to do the sameHIT twice, which is controlled by the
Amazon Mechanical Turk Web Service. Atotal of 174 different human subjects worked on the 50 HITs, producing 19,018different verbs. After removing the empty and the bad submissions, and afternormalising the verbs, we ended up with a total of 17,821 verbs, i.e., 71.28 verbsper noun-noun compound on average, not necessarily distinct.
Since many workers did not strictly follow the instructions, we performed
some automatic cleaning of the results, followed by a manual check and cor-rection, when it was necessary. First, some workers included the target nouns,the complementiser
that, or determiners like
a and
the, in addition to the para-phrasing verb, in which cases we removed this extra material. For example,
starshape was paraphrased as
shape that looks like a star or as
looks like a insteadof just
looks like. Second, the instructions required that a paraphrase be a se-quence of one or more verb forms possibly followed by a preposition (complexprepositions like
because of were allowed), but in many cases the proposed para-phrases contained words belonging to other parts of speech, e.g., nouns (
is inthe shape of,
has responsibilities of,
has the role of,
makes people have,
is partof,
makes use of) or predicative adjectives (
are local to,
is full of); we filteredout all such paraphrases. In case a paraphrase contained an adverb, e.g.,
occuronly in,
will eventually bring, we removed the adverb and kept the paraphrase.
Third, we normalised the verbal paraphrases by removing the leading modals(e.g.,
can cause becomes
cause), perfect tense
have and
had (e.g.,
have joinedbecomes
joined), or continuous tense
be (e.g.,
is donating becomes
donates). Weconverted complex verbal construction of the form ‘
<raising verb> to be' (e.g.,
appear to be,
seems to be,
turns to be,
happens to be,
is expected to be) to just
be. We further removed present participles introduced by
by, e.g.,
are caused
by peeling becomes
are caused. Furthermore, we filtered out any paraphrase thatinvolved
to as part of the infinitive of a verb different from
be, e.g.,
is willing todonate or
is painted to appear like are not allowed. We also added
be when it wasmissing in passive constructions, e.g.,
made from became
be made from. Finally,we lemmatised the conjugated verb forms using
WordNet, e.g.,
comes from be-comes
come from, and
is produced from becomes
be produced from. We also fixedsome occasional spelling errors that we noticed, e.g.,
bolongs to,
happens becasueof,
is mmade from.
The resulting lexicon of human-proposed paraphrasing verbs with corre-
sponding frequencies, and some other lexicons, e.g., a lexicon of the first verbsproposed by each worker only, and a lexicon of paraphrasing verbs automaticallyextracted from the Web as described in [12], are released under the
CreativeCommons License4, and can be downloaded from the
Multiword ExpressionsWebsite: http://multiword.sf.net. See [13] for additional details.
Experiments and Evaluation
We performed a number of experiments in order to assess both the quality ofthe created lexicon and the feasibility of the idea of using paraphrasing verbs tocharacterise noun compounds' semantics.
For each noun-noun compound from the
Levi-250 dataset, we constructed two
frequency vectors
h (human) and
−
p (programme). The former is composed of
the above-described human-proposed verbs (after lemmatisation) and their cor-responding frequencies, and the latter contains verbs and frequencies that wereautomatically extracted from the Web, as described in [12]. We then calculated
the cosine correlation coefficient between
h and
−
p as follows:
cos(
h , −
i=1
i
Table 3 shows human- and programme-proposed vectors for sample noun-
noun compounds together with the corresponding cosine. The average cosinecorrelation (in %s) for all 250 noun-noun compounds is shown in Table 4. Sincethe workers were instructed to provide at least three paraphrasing verbs pernoun-noun compound, and they tried to comply, some bad verbs were generatedas a result. In such cases, the very first verb proposed by a worker for a givennoun-noun compound is likely to be the best one. We tested this hypothesis bycalculating the cosine using these first verbs only. As the last two columns of thetable show, using all verbs produces consistently better cosine correlation, whichsuggests that there are many additional good human-generated verbs amongthose that follow the first one. However, the difference is 1-2% only and is notstatistically significant.
Noun Compound Interpretation Using Paraphrasing Verbs
0.96 "blood donor" NOMINALIZATION:AGENTHuman: give(30), donate(16), supply(8), provide(6), share(2), contribute(1), volunteer(1),offer(1), choose(1), hand over(1),
. .
Progr.: give(653), donate(395), receive(74), sell(41), provide(39), supply(17), be(13), match(11),contribute(10), offer(9),
. .
0.93 "city wall" HAVE2Human: surround(24), protect(10), enclose(8), encircle(7), encompass(3), be in(3), contain(2),snake around(1), border(1), go around(1),
. .
Progr.: surround(708), encircle(203), protect(191), divide(176), enclose(72), separate(49),ring(41), be(34), encompass(25), defend(25),
. .
0.91 "disease germ" CAUSE1Human: cause(20), spread(5), carry(4), create(4), produce(3), generate(3), start(2), promote(2),lead to(2), result in(2),
. .
Progr.: cause(919), produce(63), spread(37), carry(20), propagate(9), create(7), transmit(7),be(7), bring(5), give(4),
. .
0.89 "flu virus" CAUSE1Human: cause(19), spread(4), give(4), result in(3), create(3), infect with(3), contain(3), be(2),carry(2), induce(1),
. .
Progr.: cause(906), produce(21), give(20), differentiate(17), be(16), have(13), include(11),spread(7), mimic(7), trigger(6),
. .
0.89 "gas stove" USEHuman: use(20), run on(9), burn(8), cook with(6), utilize(4), emit(3), be heated by(2), need(2),consume(2), work with(2),
. .
Progr.: use(98), run on(36), burn(33), be(25), be heated by(10), work with(7), be used with(7),leak(6), need(6), consume(6),
. .
0.89 "collie dog" BEHuman: be(12), look like(8), resemble(2), come from(2), belong to(2), be related to(2), becalled(2), be classified as(2), be made from(1), be named(1),
. .
Progr.: be(24), look like(14), resemble(8), be border(5), feature(3), come from(2), tend(2), bebearded(1), include(1), betoken(1),
. .
0.87 "music box" MAKE1Human: play(19), make(12), produce(10), emit(5), create(4), contain(4), provide(2), generate(2),give off(2), include(1),
. .
Progr.: play(104), make(34), produce(18), have(16), provide(14), be(13), contain(9), access(8),say(7), store(6),
. .
0.87 "cooking utensils" FORHuman:
be required for(2),
be used during(2), be found in(2), be utilized in(2), involve(2),
. .
Progr.: be used for(43), be used in(11), make(6), be suited for(5), replace(3), be used during(2),facilitate(2), turn(2), keep(2), be for(1),
. .
Table 3. Human- and programme-proposed vectors, and cosines for samplenoun-noun compounds. The common verbs for each vector pair are underlined.
Min # of Number of
Correlation with Humans
Web Verbs Compounds Using All Verbs First Verb Only
Table 4. Average cosine correlation (in %s) between human- andprogramme-generated verbs for the Levi-250 dataset. Shown are the resultsfor different limits on the minimum number of programme-generated Web verbs. Thelast column shows the cosine when only the first verb proposed by each worker is used.
A limitation of the Web-based verb-generating method is that it could not
provide paraphrasing verbs for 14 of the noun-noun compounds, in which casesthe cosine was zero. If the calculation was performed for the remaining 236compounds only, the cosine increased by 2%. Table 4 shows the results whenthe cosine calculations are limited to compounds with at least 1, 3, 5 or 10different verbs. We can see that the correlation increases with the minimumnumber of required verbs, which means that the extracted verbs are generallygood, and part of the low cosines are due to an insufficient number of extractedverbs. Overall, all cosines in Table 4 are in the 30-37%, which corresponds to amedium correlation [14].
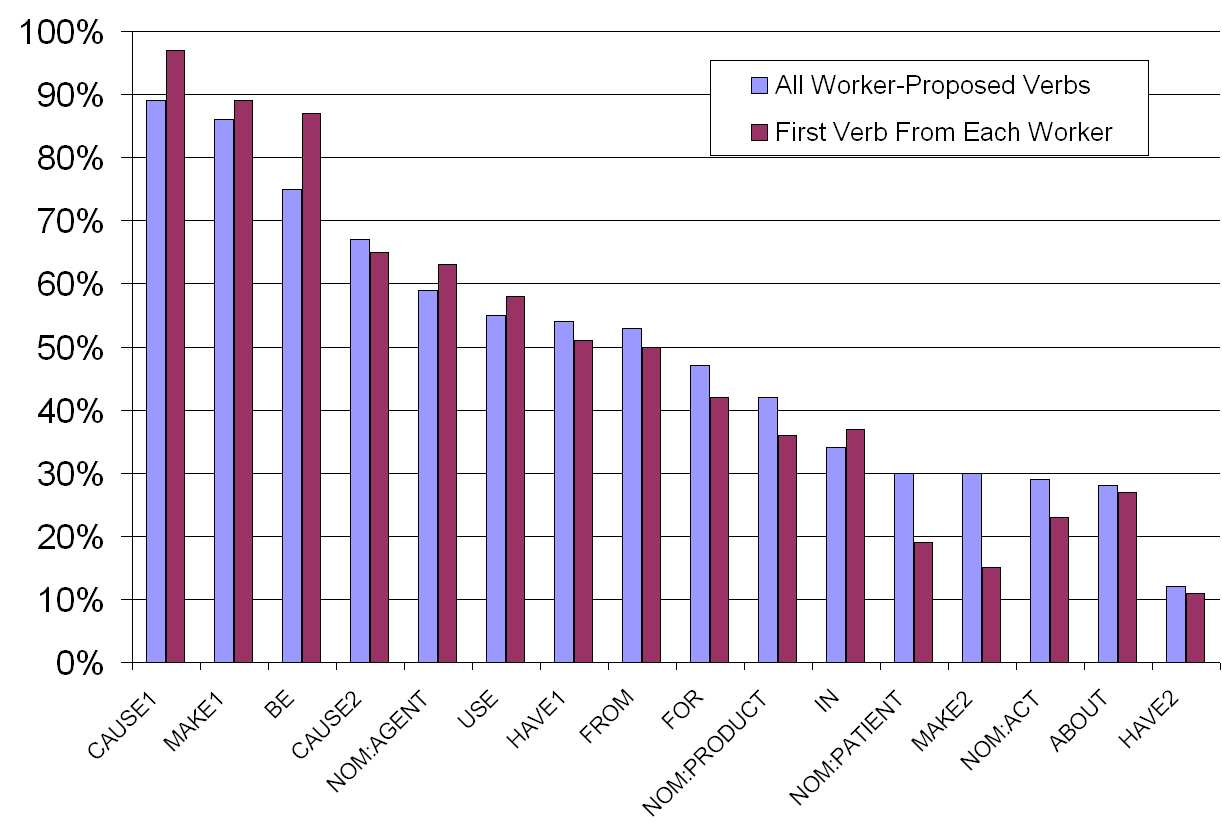
Fig. 3. Cosine correlation (in %s) between the human- and the programme-generated verbs from the Levi-250 dataset aggregated by relation: using allhuman-proposed verbs vs. only the first verb from each worker.
Noun Compound Interpretation Using Paraphrasing Verbs
Fig. 4. Average cosine correlation (in %s) between the human- and theprogramme-generated verbs for the Levi-250 dataset calculated for eachnoun compound (left) and aggregated by relation (right): using all human-proposed verbs vs. only the first verb from each worker.
We further compared the human- and the programme-generated verbs aggre-
gated by relation. Given a relation like HAVE1, we collected all verbs belonging tonoun-noun compounds from that relation together with their frequencies. Froma vector-space model point of view, we summed their corresponding frequencyvectors. We did this separately for the human- and the programme-generatedverbs, and we then compared the corresponding pairs of summed vectors sepa-rately for each relation.
Figure 3 shows the cosine correlations for each of the 16 relations using all
human-proposed verbs and only the first verb from each worker. We can see avery-high correlation (mid-70% to mid-90%) for relations like CAUSE1, MAKE1,BE, but low correlation 11-30% for reverse relations like HAVE2 and MAKE2, andfor most nominalisations (except for NOM:AGENT). Interestingly, using only thefirst verb improves the results for highly-correlated relations, but damages low-correlated ones. This suggests that when a relation is more homogeneous, thefirst verbs proposed by the workers are good enough, and the following verbsonly introduce noise. However, when the relation is more heterogeneous, theextra verbs are more likely to be useful. As Figure 4 shows, overall the averagecosine correlation is slightly higher when all worker-proposed verbs are usedvs. the first verb from each worker only: this is true both when comparing theindividual noun-noun compounds and when the comparison is performed for the16 relations. The figure also shows that while the cosine correlation for individualnoun-noun compounds is in the low-30%, for relations it is almost 50%.
Finally, we tested whether the paraphrasing verbs are good features to use
in a nearest-neighbour classifier. Given a noun-noun compound, we used thehuman-proposed verbs as features to predict Levi's RDP for that compound.
In this experiment, we only used those noun-noun compounds which are notnominalisations, i.e., for which Levi has an RDP provided; this left us with214 examples (Levi-214 dataset) and 12 classes. We performed leave-one-out
Accuracy Coverage Avg #feats Avg Σfeats
Human: all v
Human: first v from each worker 72.3±6.4
Web: v + p + c
Web: v + p
Web: v + c
Web: p + c
Baseline (majority class)
Table 5. Predicting Levi's RDP on the Levi-214 dataset using verbs v, prepo-sitions p, and coordinating conjunctions c as features: leave-one-out cross-validation. Shown are micro-averaged accuracy and coverage in %s, followed by aver-age number of features and average sum of feature frequencies per example.
cross-validation experiments with a 1-nearest-neighbor classifier (using TF.IDF-weighting and the Dice coefficient5 as a similarity measure, as in [15]), trying topredict the correct RDP for the testing example. The results are shown in Table5. We achieved 78.4% accuracy using all verbs, and 72.3% with the first verbfrom each worker. This result is very strong for a 12-way classification problem,and supports the hypothesis that the paraphrasing verbs are very importantfeatures for the task of noun-noun compound interpretation.
Table 5 also shows the results when verbs, prepositions and coordinating con-
junctions automatically extracted from the Web are used as features. As we cansee, using prepositions alone only yields about 33% accuracy, which is a statisti-cally significant improvement over the majority-class baseline, but is well belowthe classifier performance when using verbs. Overall, the most important Web-derived features are the verbs: they yield 45.8% accuracy when used alone, and50% when used together with prepositions. Adding coordinating conjunctionshelps a bit with verbs, but not with prepositions. Note however that none of thedifferences between the different feature combinations involving verbs are statis-tically significant. However, the difference between using Web-derived verbs andusing human-proposed verbs (78.4% vs. 50%) is very statistically significant, andsuggests that the human-proposed verbs could be considered an upper bound onthe accuracy that could be achieved with automatically extracted features.
Table 5 also shows the average number of distinct features and the sum of
feature counts per example. As we can see, for Web-derived features, there isa strong positive correlation between number of extracted features and classi-fication accuracy, the best result being achieved with more than 200 featuresper example. Note however, that using human-proposed verbs yields very highaccuracy with seven times less features on average.
5 Given two TF.IDF-weighted frequency vectors A and B, we compare them using the
following generalised Dice coefficient: Dice(A, B) = 2× i=1 min(ai,bi)
i=1 i
Noun Compound Interpretation Using Paraphrasing Verbs
Interpreting noun compounds in terms of sets of fine-grained verbs that aredirectly usable in paraphrases of the target noun-noun compounds can be usefulfor a number of NLP tasks, e.g., for noun compound translation in isolation[3, 16, 17], for paraphrase-augmented machine translation [18–21], for machinetranslation evaluation [22, 23], for summarisation evaluation [24], etc.
As we have shown above (see [11, 12, 15] for additional details and discussion
on our experiments), assuming annotated training data, the paraphrasing verbscan be used as features to predict abstract relations like CAUSE, USE, MAKE, etc.
Such coarse-grained relations can in turn be helpful for other applications, e.g.,for recognising textual entailment as shown by Tatu&Moldovan [25]. Note how-ever, that, for this task, it is possible to use our noun compound paraphrasingverbs directly as explained in Appendix B of [11].
In information retrieval, the paraphrasing verbs can be used for index nor-
malisation [26], query expansion, query refinement, results re-ranking, etc. Forexample, when querying for migraine treatment, pages containing good para-phrasing verbs like relieve or prevent could be preferred.
In data mining, the paraphrasing verbs can be used to seed a Web search
that looks for particular classes of NPs such as diseases, drugs, etc. For exam-ple, after having found that prevent is a good paraphrasing verb for migrainetreatment, we can use the query6 "* which prevents migraines" to obtain dif-ferent treatments/drugs for migraine, e.g., feverfew, Topamax, natural treatment,magnesium, Botox, Glucosamine, etc. Using a different paraphrasing verb, e.g.,using "* reduces migraine" can produce additional results: lamotrigine, PFOclosure, Butterbur Root, Clopidogrel, topamax, anticonvulsant, valproate, closureof patent foramen ovale, Fibromyalgia topamax, plant root extract, Petadolex,Antiepileptic Drug Keppra (Levetiracetam), feverfew, Propranolol, etc. This issimilar to the idea of a relational Web search of Cafarella&al. [27], whose systemTextRunner serves four types of relational queries, among which there is oneasking for all entities that are in a particular relation with a given target entity,e.g., "find all X such that X prevents migraines".
Conclusion and Future Work
In this paper, we explored and experimentally tested the idea that, in general, thesemantics of a given noun-noun compound can be characterised by the set of allpossible paraphrasing verbs that can connect the target nouns, with associatedweights. The verbs we used were fine-grained, directly usable in paraphrases,and using multiple of them for a given noun-noun compound allowed for betterapproximating its semantics.
Using Amazon's Mechanical Turk, we created a new resource for noun-noun
compound interpretation based on paraphrasing verbs, and we demonstrated
6 Here "*" is the Google star operator, which can substitute one or more words. In
fact, it is not really needed in this particular case.
experimentally that verbs are especially useful features for predicting abstractrelations like Levi's RDPs. We have already made the resource publicly available[13]; we hope that by doing so, we will inspire further research in the direction ofparaphrase-based noun compound interpretation, which opens the door to prac-tical applications in a number of NLP tasks including but not limited to machinetranslation, text summarisation, question answering, information retrieval, tex-tual entailment, relational similarity, etc.
The present situation with noun compound interpretation is similar to that
with word sense disambiguation: in both cases, there is a general agreement thatthe research is important and much needed, there is a growing interest in per-forming further research, and a number of competitions are being organised, e.g.,as part of SemEval [28]. Still, there are very few applications of noun compoundinterpretation in real NLP tasks (e.g., [19] and [25]). We think that increasingthis number is key for the advancement of the field, and we believe that turningto paraphrasing verbs could help bridge the gap between research interest andpractical applicability for noun compound interpretation.
Acknowledgments. This research was supported in part by the FP7 projectAsIsKnown, by FP7-REGPOT-2007-1 SISTER and by NSF DBI-0317510.
1. Downing, P.: On the creation and use of English compound nouns. Language (53)
2. Levi, J.: The Syntax and Semantics of Complex Nominals. Academic Press, New
3. Baldwin, T., Tanaka, T.: Translation by machine of compound nominals: Getting
it right. In: Proceedings of the ACL 2004 Workshop on Multiword Expressions:Integrating Processing. (2004) 24–31
4. Warren, B.: Semantic patterns of noun-noun compounds. In: Gothenburg Studies
in English 41, Goteburg, Acta Universtatis Gothoburgensis. (1978)
5. Nastase, V., Szpakowicz, S.: Exploring noun-modifier semantic relations. In:
Fifth International Workshop on Computational Semantics (IWCS-5), Tilburg,The Netherlands (2003) 285–301
6. Girju, R., Moldovan, D., Tatu, M., Antohe, D.: On the semantics of noun com-
pounds. Journal of Computer Speech and Language - Special Issue on MultiwordExpressions 4(19) (2005) 479–496
7. Rosario, B., Hearst, M.: Classifying the semantic relations in noun compounds via
a domain-specific lexical hierarchy. In: Proceedings of EMNLP. (2001) 82–90
8. Lauer, M.: Designing Statistical Language Learners: Experiments on Noun Com-
pounds. PhD thesis, Dept. of Computing, Macquarie University, Australia (1995)
9. Finin, T.: The Semantic Interpretation of Compound Nominals. PhD thesis,
University of Illinois, Urbana, Illinois (1980)
10. Nakov, P., Hearst, M.: Using verbs to characterize noun-noun relations. In: AIMSA.
Volume 4183 of LNCS., Springer (2006) 233–244
11. Nakov, P.: Using the Web as an Implicit Training Set: Application to Noun Com-
pound Syntax and Semantics. PhD thesis, EECS Department, University of Cali-fornia, Berkeley, UCB/EECS-2007-173 (2007)
Noun Compound Interpretation Using Paraphrasing Verbs
12. Nakov, P., Hearst, M.: Solving relational similarity problems using the web as a
corpus. In: Proceedings of ACL'08: HLT, Columbus, OH (2008)
13. Nakov, P.: Paraphrasing verbs for noun compound interpretation. In: Proceedings
of the LREC'08 Workshop: Towards a Shared Task for Multiword Expressions(MWE'08), Marrakech, Morocco (2008)
14. Cohen, J.: Statistical Power Analysis for the Behavioral Sciences. 2 edn. Lawrence
Erlbaum Associates, Inc., Hillsdale, NJ (1988)
15. Nakov, P., Hearst, M.: UCB: System description for SemEval Task #4. In: Pro-
ceedings of SemEval, Prague, Czech Republic (2007) 366–369
16. Grefenstette, G.: The World Wide Web as a resource for example-based machine
translation tasks. In: Translating and the Computer 21: Proceedings of the 21stInternational Conference on Translating and the Computer. (1999)
17. Tanaka, T., Baldwin, T.: Noun-noun compound machine translation: a feasibil-
ity study on shallow processing. In: Proceedings of the ACL 2003 workshop onMultiword expressions. (2003) 17–24
18. Callison-Burch, C., Koehn, P., Osborne, M.: Improved statistical machine trans-
lation using paraphrases. In: Proceedings of Human Language Technology Con-ference of the North American Chapter of the Association of Computational Lin-guistics. (2006) 17–24
Improved statistical machine translation using monolingual para-
phrases. In: Proceedings of the European Conference on Artificial Intelligence(ECAI'08), Patras, Greece (2008)
20. Nakov, P., Hearst, M.: UCB system description for the WMT 2007 shared task. In:
Proceedings of the Second Workshop on Statistical Machine Translation, Prague,Czech Republic (June 2007) 212–215
21. Nakov, P.: Improving English-Spanish statistical machine translation: Experi-
ments in domain adaptation, sentence paraphrasing, tokenization, and recasing. In:Proceedings of the Third Workshop on Statistical Machine Translation (WMT),Columbus, OH (2008)
22. Russo-Lassner, G., Lin, J., Resnik, P.: A paraphrase-based approach to machine
translation evaluation. Technical Report LAMP-TR-125/CS-TR-4754/UMIACS-TR-2005-57, University of Maryland (August 2005)
23. Kauchak, D., Barzilay, R.: Paraphrasing for automatic evaluation. In: Proceedings
Human Language Technology Conference of the North American Chapter of theAssociation of Computational Linguistics. (2006) 455–462
24. Zhou, L., Lin, C.Y., Hovy, E.: Re-evaluating machine translation results with
paraphrase support. In: Proceedings of the 2006 Conference on Empirical Methodsin Natural Language Processing, Sydney, Australia (July 2006) 77–84
25. Tatu, M., Moldovan, D.: A semantic approach to recognizing textual entailment.
In: Proceedings of HLT. (2005) 371–378
26. Zhai, C.: Fast statistical parsing of noun phrases for document indexing. In:
Proceedings of the fifth conference on Applied natural language processing, SanFrancisco, CA, USA, Morgan Kaufmann Publishers Inc. (1997) 312–319
27. Cafarella, M., Banko, M., Etzioni, O.: Relational Web search. Technical Report
2006-04-02, University of Washington, Department of Computer Science and En-gineering (2006)
28. Girju, R., Nakov, P., Nastase, V., Szpakowicz, S., Turney, P., Yuret, D.: Semeval-
2007 task 04: Classification of semantic relations between nominals. In: Proceedingsof SemEval, Prague, Czech Republic (2007) 13–18
Source: http://biotext.berkeley.edu/papers/aimsa2008.pdf
Smoking - The Facts Cigarette smoking is the greatest single cause of il ness and premature death in the UK. This leafletgives reasons why smoking is so harmful. It also lists the benefits of stopping, and where to go forhelp. Some initial facts and figures About 100,000 people in the UK die each year due to smoking. Smoking-related deaths are mainly due tocancers, chronic obstructive pulmonary disease (COPD) and heart disease.
- isolate and purify caffeine from tea leaves - characterize the caffeine extracted from tea leaves - calculate the percent yield of caffeine Highlighted Concepts Genus: Camellia Species: C. sinensis Binomial name: Camellia sinensis - a small shrub about 3 to 6 feet tall - flowers with small white blossoms that have a delightful scent during fall